@BENCH: Benchmarking Vision-Language Models for Human-centered Assistive Technology
WACV 2025
|
1Karlsruhe Institute of Technology
|
2Li Auto Inc.
|
|
|
*Joint First Authors
|
†Corresponding Author
|
|
Abstract
As Vision-Language Models (VLMs) advance, human-centered Assistive Technologies (ATs) for helping People with Visual Impairments (PVIs) are evolving into generalists, capable of performing multiple tasks simultaneously. However, benchmarking VLMs for ATs remains underexplored. To bridge this gap, we first create a novel AT benchmark (@Bench). Guided by a pre-design user study with PVIs, our benchmark includes the five most crucial vision-language tasks: Panoptic Segmentation, Depth Estimation, Optical Character Recognition (OCR), Image Captioning, and Visual Question Answering (VQA). Besides, we propose a novel AT model (@Model) that addresses all tasks simultaneously and can be expanded to more assistive functions for helping PVIs. Our framework exhibits outstanding performance across tasks by integrating multi-modal information, and it offers PVIs a more comprehensive assistance. Extensive experiments prove the effectiveness and generalizability of our framework.
Model and Benchmark Overview
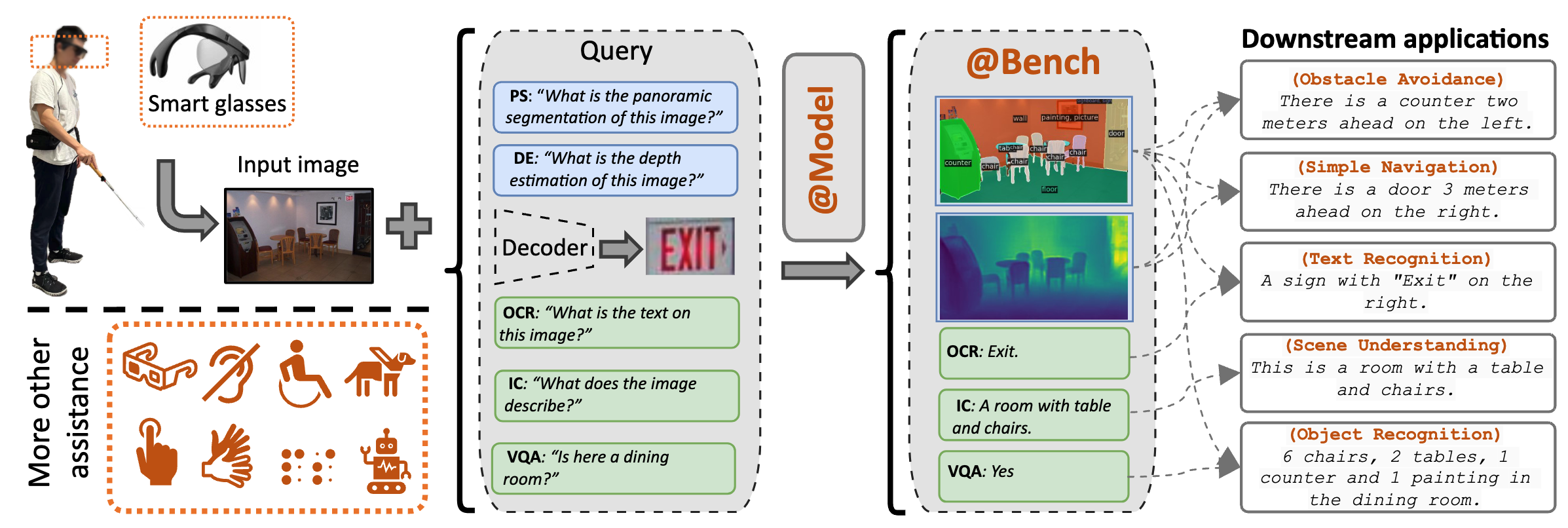
Fig. 1: Overview of our Assistive Technology Model (@MODEL) and Benchmark (@BENCH). @MODEL can perform vision-language tasks all at once, including: Panoptic Segmentation, Depth Estimation, Image Captioning, Optical Character Recognition and Visual Question Answering. All tasks of @BENCH are selected by People with Visual Impairments (PVIs) to evaluate VLMs for AT.
|
Proposed Benchmark: @Bench
User Study
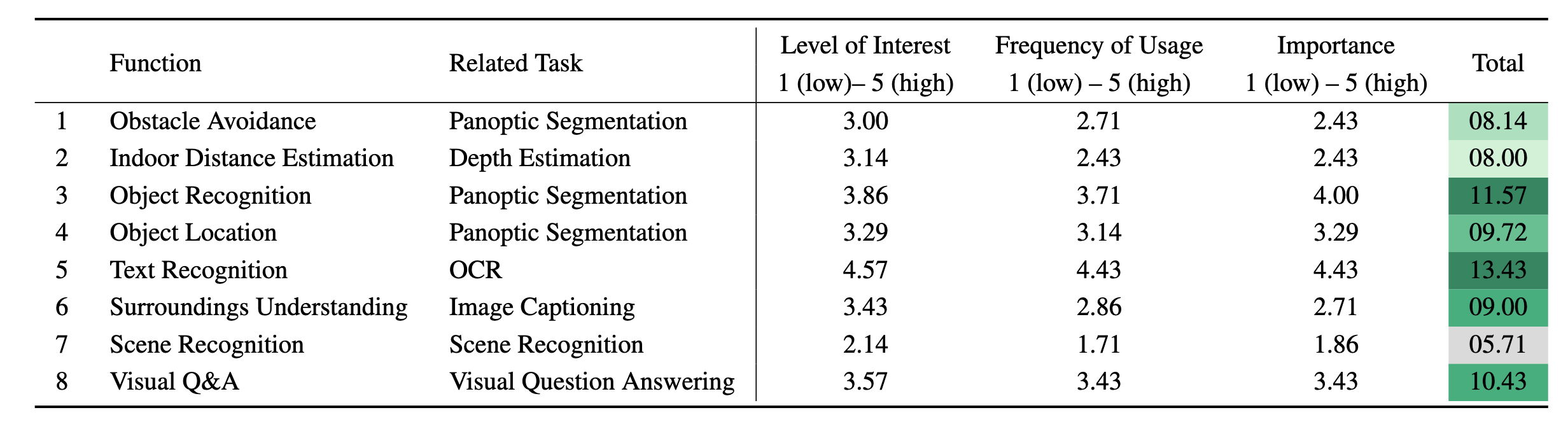
Table 1: Quantitative result of the user study. Potential functions can be achieved via related tasks, which are listed in the questionnaires for the user study. Note: all scores are averages across 7 participants.
|
To build the AT benchmark, we conducted a pre-study with 2 accessibility experts to develop a reasonable questionnaire. Based on their suggestions and multiple discussions, we further organized a user-centered study with 7 participants who are blind or have low vision. The goal was to identify which vision-language tasks are beneficial for the target group and meet their requirements.
Assistive Tasks
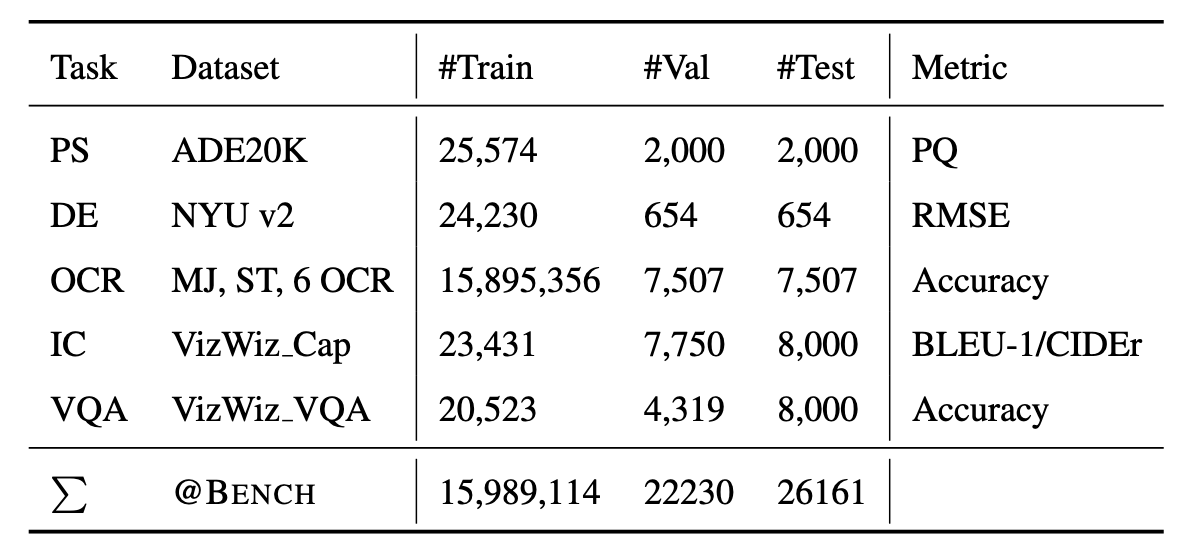
Table 2: Statistic of pre-selected tasks and datasets in @BENCH. Note that some datasets do not have a test subset, so use val subset for evaluation. The 6 OCR datasets are IC13, IC15, IIIT5K, SVT, SVTP and CUTE.
|
Guided by the user study, @BENCH contains 5 tasks that are extremely relevant to the daily lives of PVIs. We give an overview of all tasks and the corresponding datasets in Table 2.
- Panoptic Segmentation. It is the task that combines both semantic segmentation and instance segmentation, aiming to simultaneously recognize all object instances in an image and segment them by category, helping blind people perceive the surroundings more accurately.
- Depth Estimation. It is the task of measuring the distance of each pixel relative to the user’s camera.
- Optical Character Recognition. It is the conversion of images of typed, handwritten or printed text into machine-encoded text.
- Image Captioning. It is a challenging task that involves generating human-like and coherent natural language descriptions for images.
- Visual Question Answering. It requires the model to take as input an image and a free-form, open-ended, natural language question. It produces or selects a natural language answer as output.
Efficiency-Performance Trade-off
In designing models for assistive systems, an optimal balance between efficiency and performance is essential. Normally, the performance of VLMs can be easily measured by task-specific metrics. For efficiency, there are few common choices: the number of parameters, FLOPs and inference time. To compare with previous methods, we evaluate efficiency through the number of parameters.
Proposed Model: @Model
Model Architecture
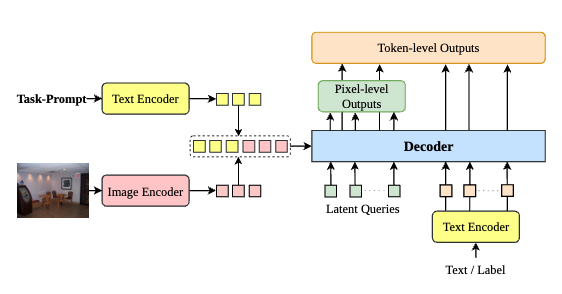
Fig. 2: Overall architecture of @MODEL. We propose task-based prompts to unify inputs and perform different tasks all at once.
|
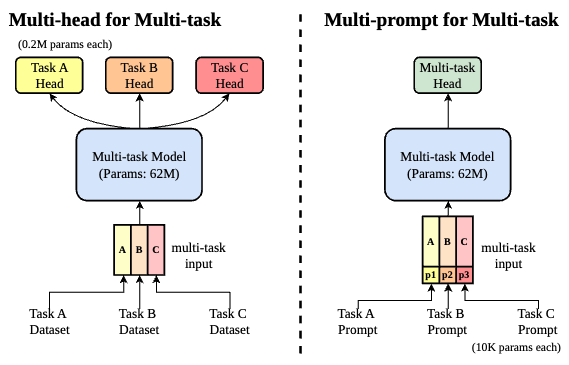
Fig. 3: Paradigms of multi-task methods. Our @MODEL incorporates task-specific prompts that effectively unify tasks all at once and with almost no additional parameters.
|
As show in Fig. 2, @MODEL has two types of output: (1) pixel-level output for dense prediction, such as panoptic segmentation and dense estimation and (2) token-level output for a diverse set of language-related vision tasks, such VQA, image captioning and OCR.
Tradictional multi-task learning paradigm (in Fig. 3 left) will make the structure of the entire model very bloated, which is a major drawback for portable assistance systems. In contrast, we use task-specific prompt to build a unified input paradigm “image + prompt” as shown in Fig. 3 right.
Results
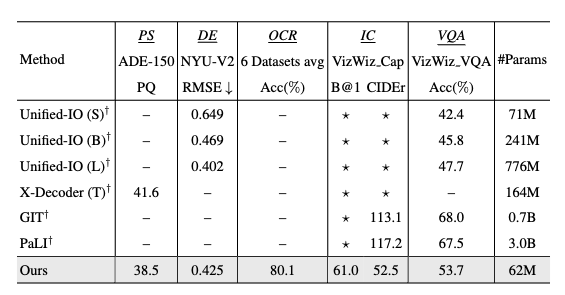
Table 3: Comparison of multi-task training @MODEL and other models. We report the multi-task training results without any pre-training and task-specific fine-tuning. Note: GIT and PaLI are LVLMs. “⋆” denotes the model has the capability for the task but does not have number reported. “–” means the model does not have the ability for the specific task. “†” means the model uses pre-trained weights for training. (B@1 = BLEU-1).
|
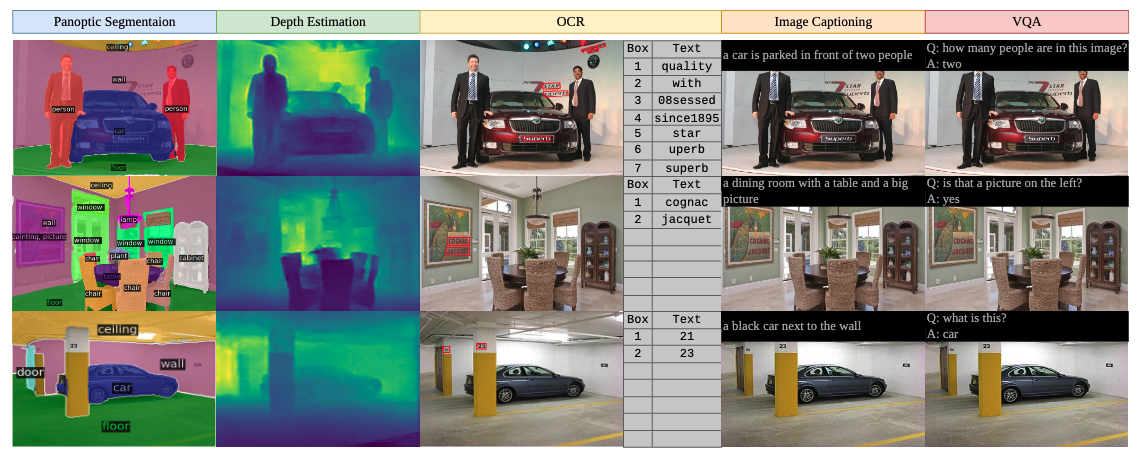
Fig. 4: Examples of multi-task training results on 5 tasks. Given one image as input our @MODEL can output all predictions.
|
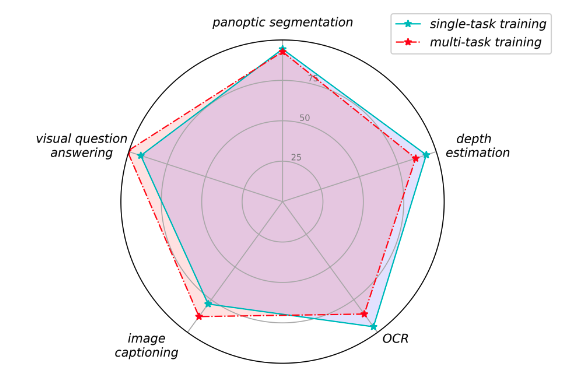
Fig. 5: Single-task and multi-task training performance (relative) against the specialized SoTA models on different tasks.
|

Table 4: Comparison of single-task training @MODEL and specialized SoTA models. Note: “model (#params)” donates the number of parameters of the model. DPT* is trained with an extra dataset.
|

Table 5: Ablation study of task-specific prompt in @MODEL. “our impl.” means our implement based on the original paper, “multi-head” means we add multiple output heads (a 3-layer MLP for each task) to the original model to achieve different tasks on @BENCH.
|
Citation
|
If you find our work useful in your research, please cite:
@inproceedings{jiang2025atbench,
title={@BENCH: Benchmarking Vision-Language Models for Human-centered Assistive Technology},
author={Jiang, Xin and Zheng, Junwei and Liu, Ruiping and Li, Jiahang and Zhang, Jiaming and Matthiesen, Sven and Stiefelhagen, Rainer},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year={2025}
}
|