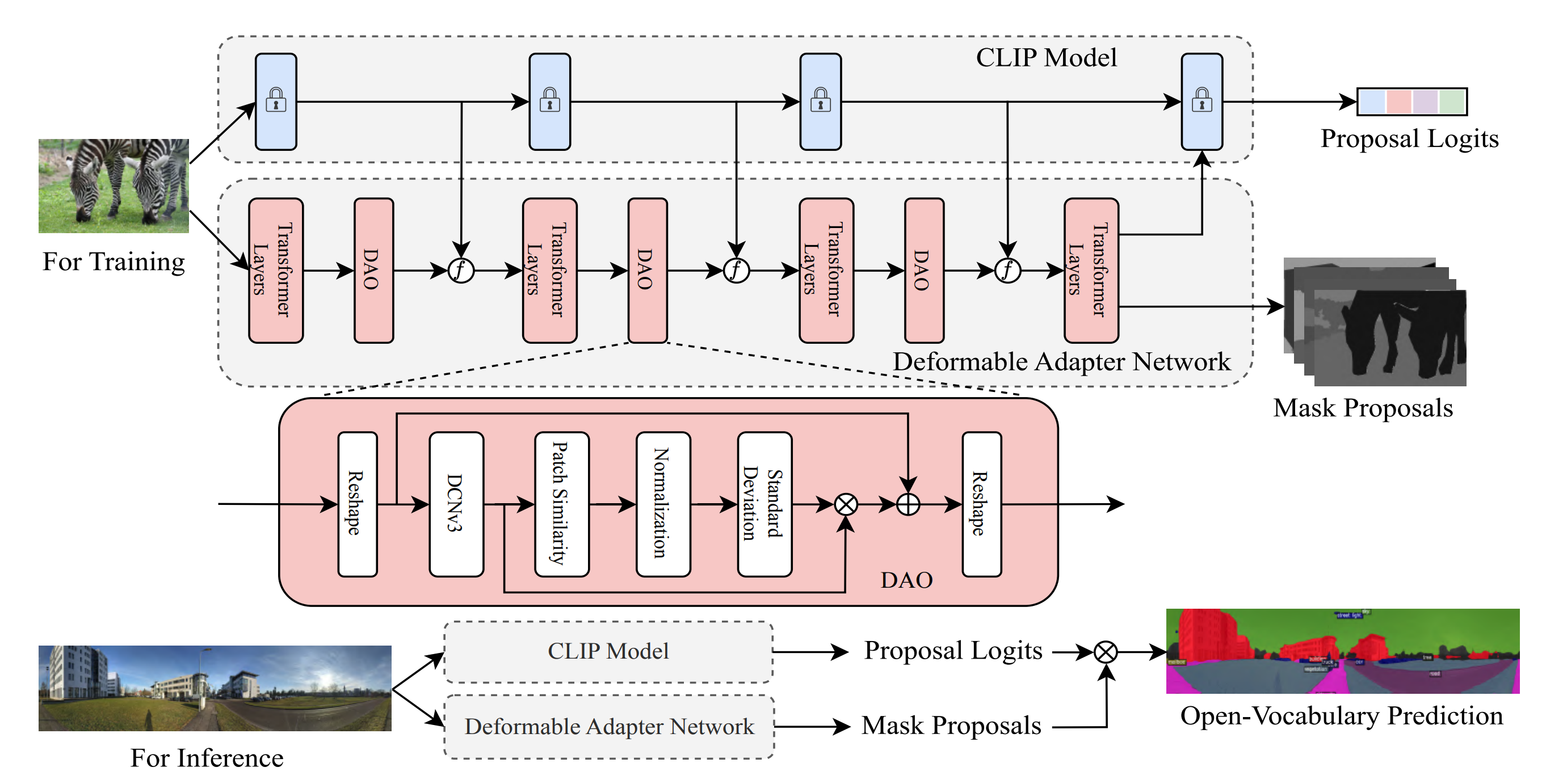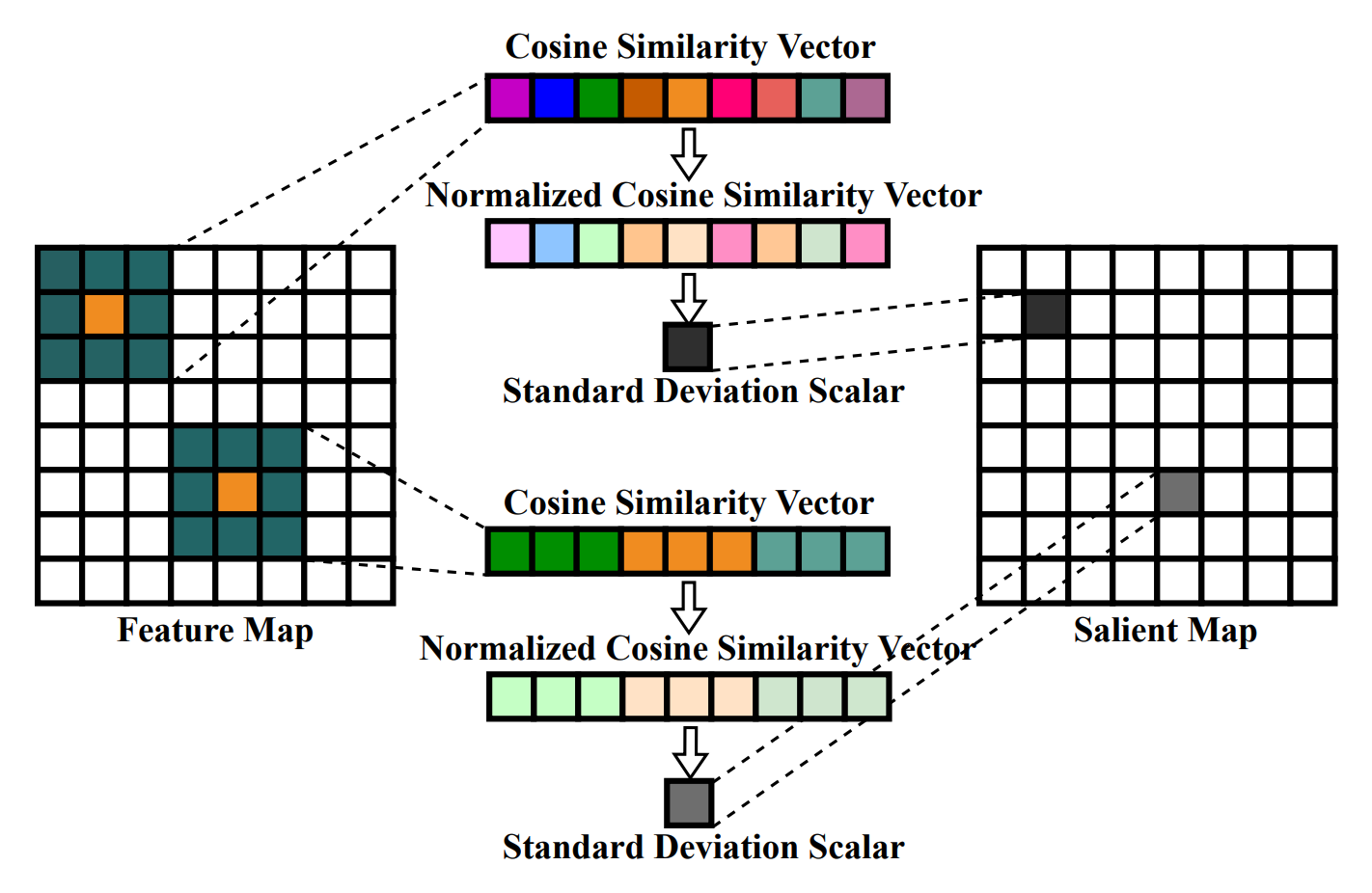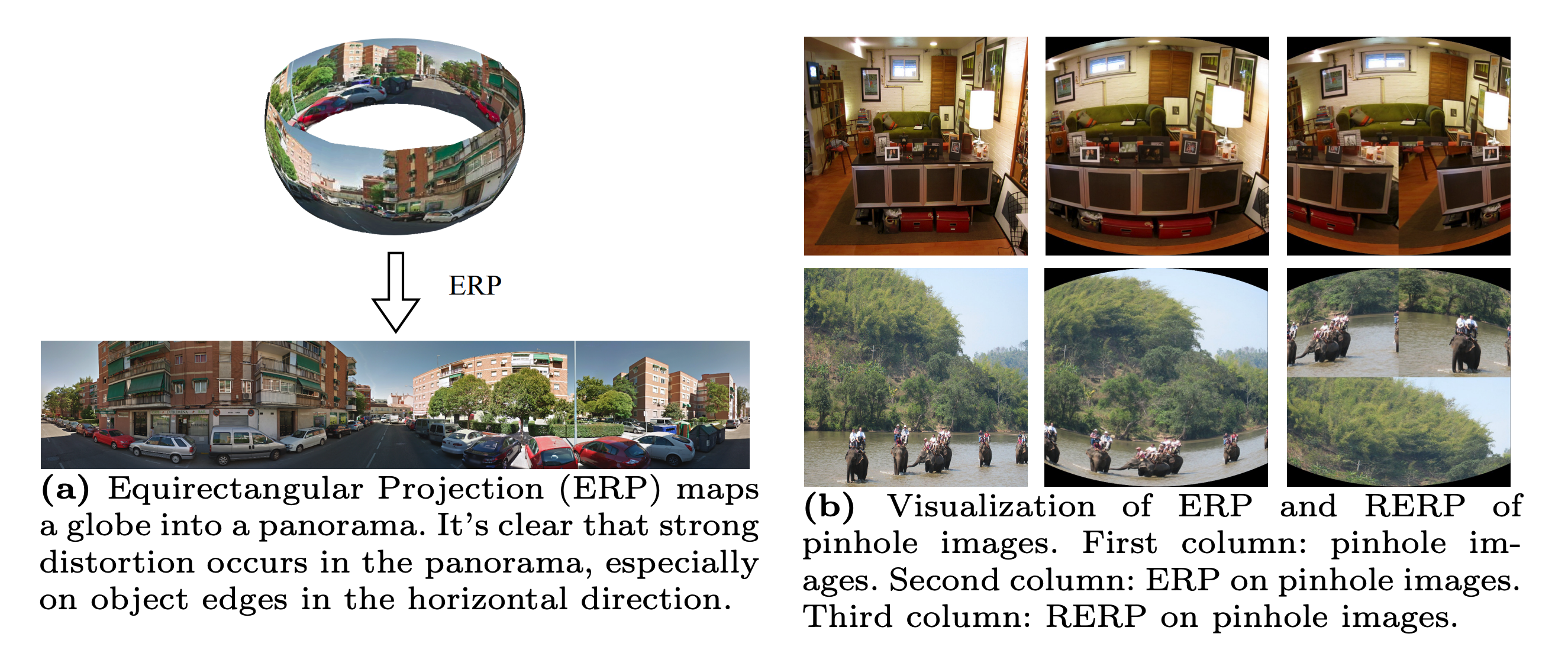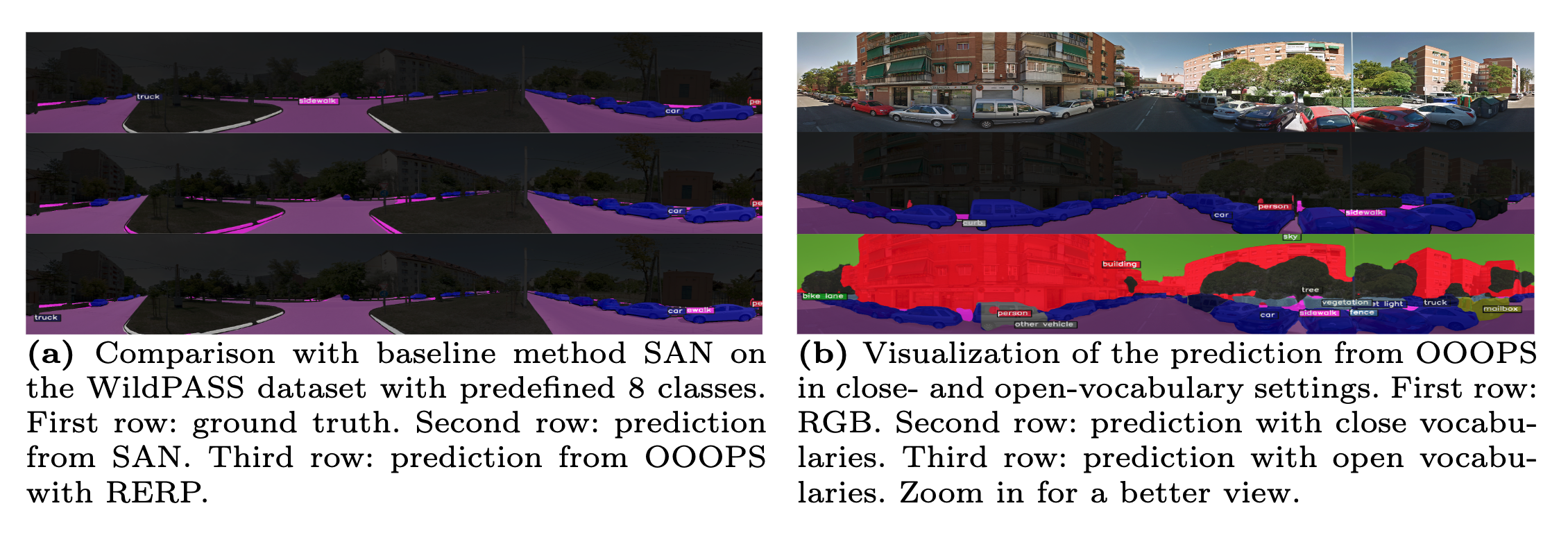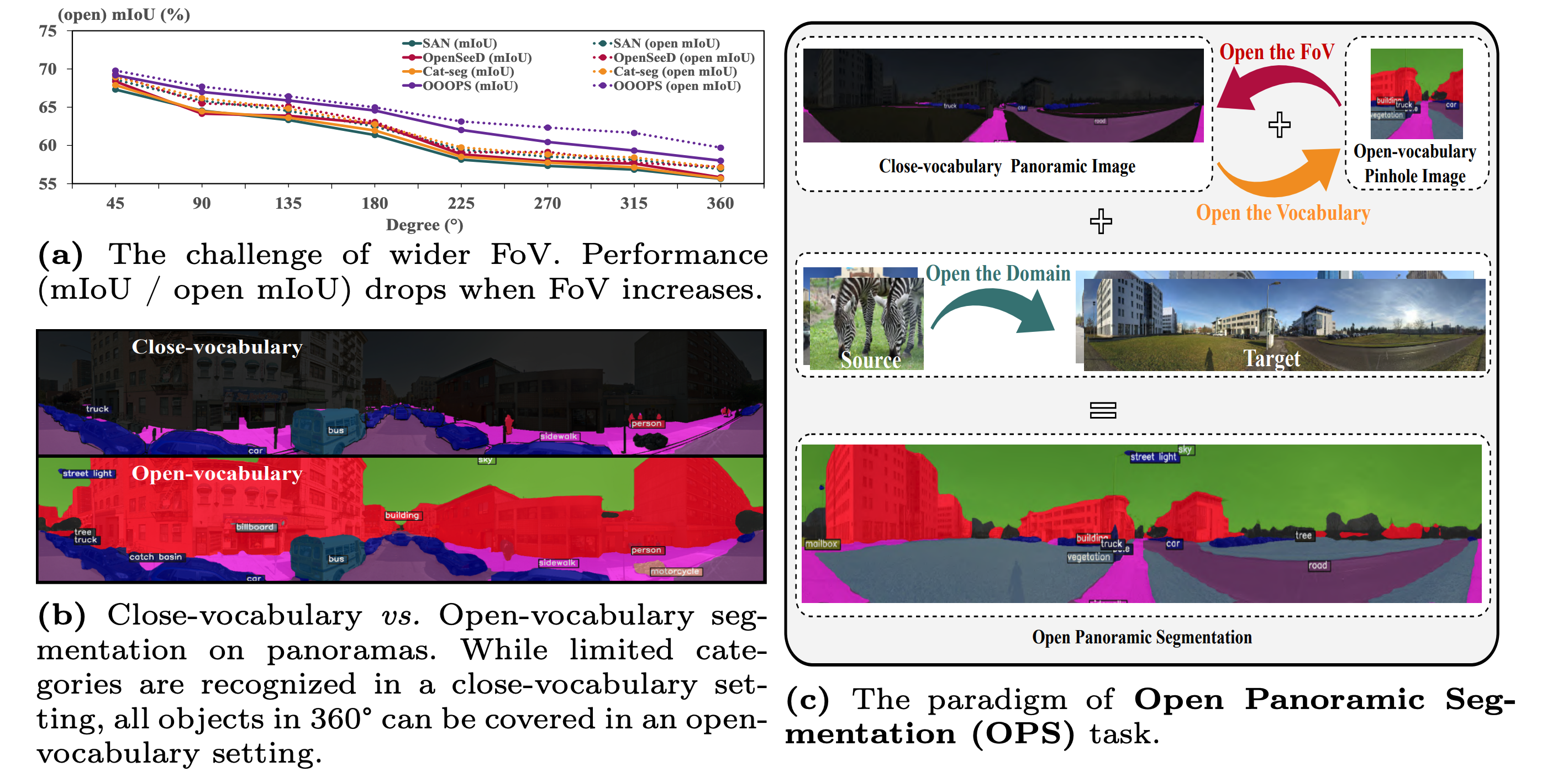
Fig. 1: (a) The challenge of existing state-of-the-art segmentation models. (b) The limitation of categories in traditional close-vocabulary panoramic segmentation tasks. (c) Our newly defined Open Panoramic Segmentation (OPS) task aims at tackling the above challenges. OPS consists of three important elements: Open the FoV targeted at the challenge of 360° FoV, Open the Vocabulary targeted at the drawback of close-vocabulary panoramic segmentation and Open the Domain targeted at the challenge of scarcity of panoramic labels.