Absolute Pose Regression (APR) predicts 6D camera poses but lacks the adaptability to unknown environments without retraining, while Relative Pose Regression (RPR) generalizes better yet requires a large image retrieval database. Visual Odometry (VO) generalizes well in unseen environments but suffers from accumulated error in open trajectories. To address this dilemma, we introduce a new task, Scene-agnostic Pose Regression (SPR), which can achieve accurate pose regression in a flexible way while eliminating the need for retraining or databases. To benchmark SPR, we created a large-scale dataset, 360SPR, with over 200K photorealistic panoramas, 3.6M pinhole images and camera poses in 270 scenes at three different sensor heights. Furthermore, a SPR-Mamba model is initially proposed to address SPR in a dual-branch manner. Extensive experiments and studies demonstrate the effectiveness of our SPR paradigm, dataset, and model. In the unknown scenes of both 360SPR and 360Loc datasets, our method consistently outperforms APR, RPR and VO.
Task Differences
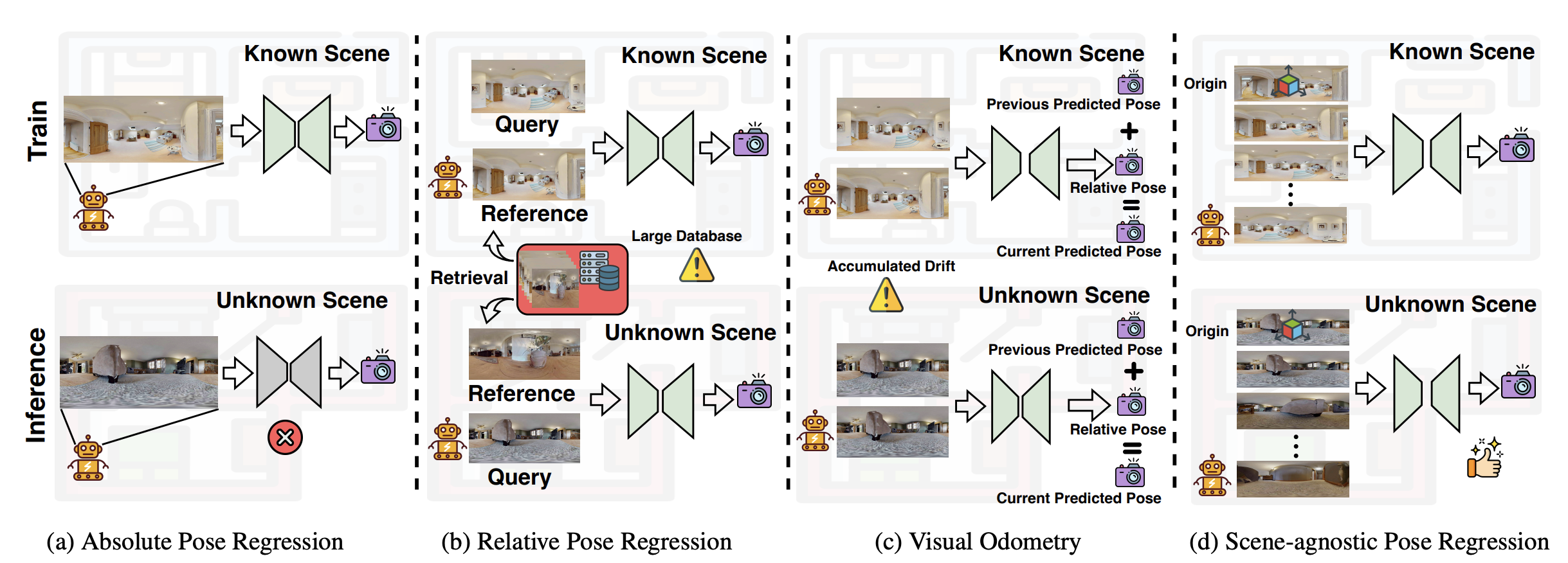
Fig. 1: Comparison of different paradigms. (a) APR is not applicable in unseen scenes without retraining. (b) RPR requires a large database for image retrieval. (c) VO suffers from accumulated drift. (d) SPR (ours) sets the first image in a sequence as the origin and predicts the relative pose of its followings, i.e., query images, avoiding the need of retraining, retrieval database or accumulated drift.
SPR Task Definition
The Scene-agnostic Pose Regression task aims to estimate the camera pose Tq of a query image Iq relative to an origin image I1 within an arbitrary scene, independent of specific scene characteristics or databases. Given a sequence of images I1, I2, . . . , Iq captured along a trajectory, the SPR task requires the model to accurately compute Tq, which represents the camera’s position and orientation for image Iq. Unlike traditional pose estimation tasks that rely on structured scenes or predefined databases, SPR operates across diverse environments, using only the image sequence itself without scene-specific priors. The goal of SPR is to develop a robust model that outputs Tq w.r.t. I1 by processing the entire sequence I1, . . . , Iq-1, Iq.
360SPR Dataset
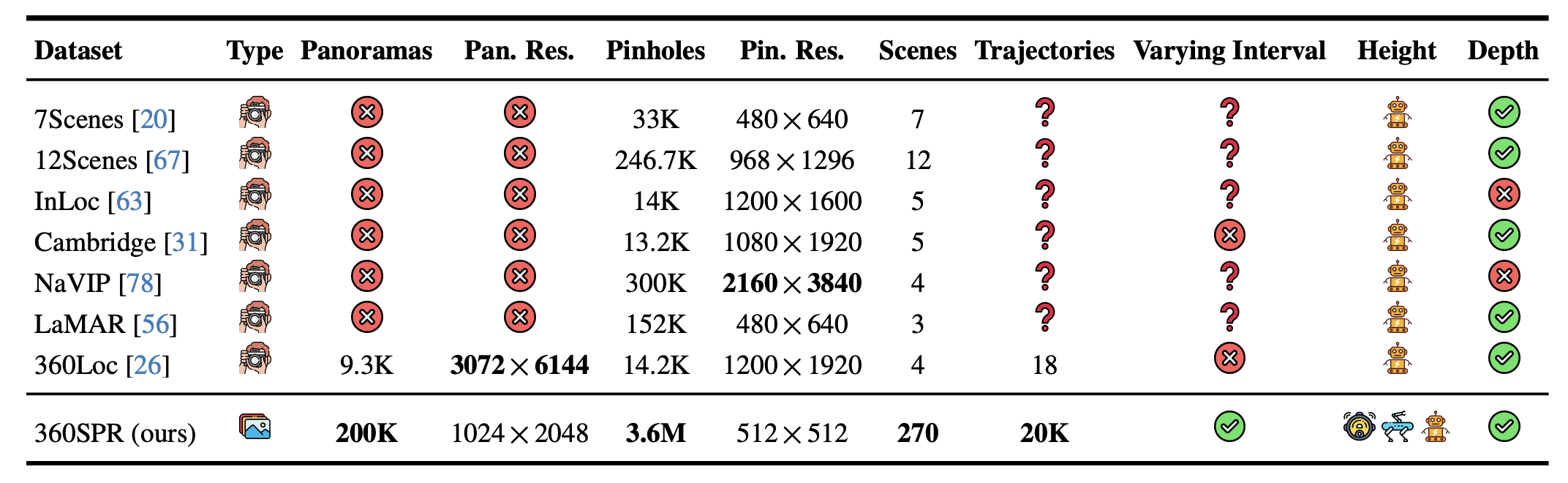
Tab. 1: Comparison of visual localization datasets. Differences include: photographic vs. photorealistic types; field of views (panoramic vs. pinhole); image sizes; the number of scenes/trajectories/intervals; and sensor heights (in sweeping , quadruped , humanoid robots). Our 360SPR has 200K panoramas and 3.6M pinhole images, offering diverse data for visual localization.
SPR-Mamba Model
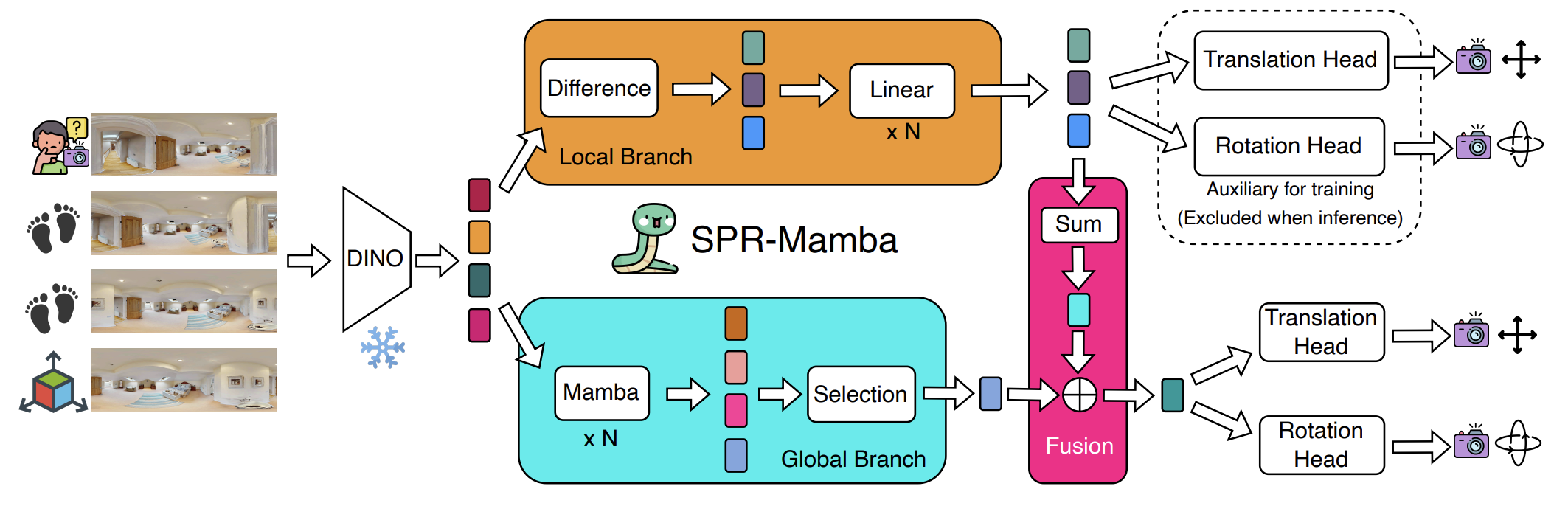
Fig. 2: Architecture of SPR-Mamba. The local branch learns the relative poses between adjacent frames while the global branch focuses on the pose between the query and the first frame in the sequence. The auxiliary heads for the local branch are not necessary after training. Note that SPR-Mamba can handle arbitrary sequence length during inference and we use 4 images for the demonstration purpose.
Experiments
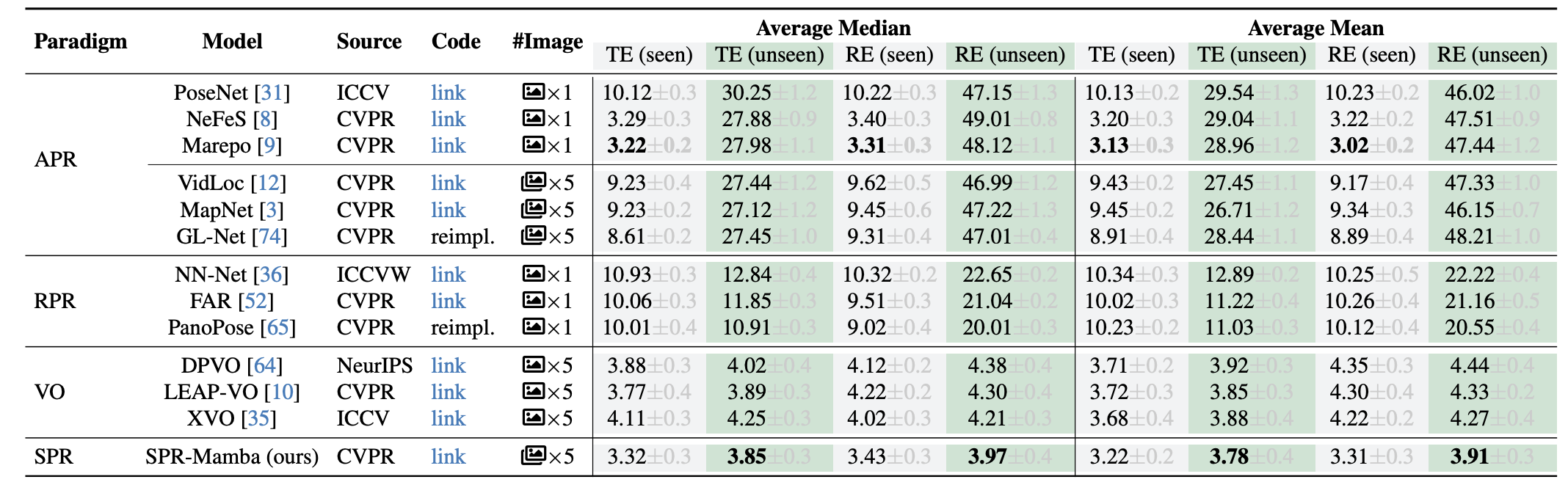
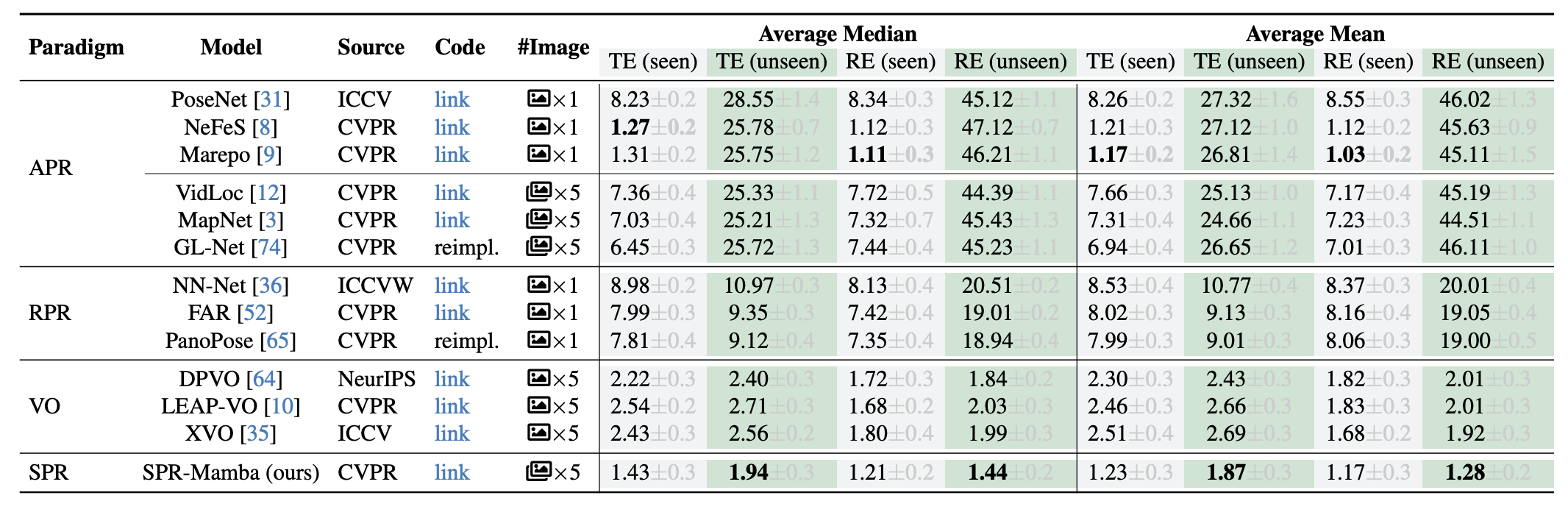
Tab. 2: Comparison of different models using different paradigms in both seen and unseen environments on the 360SPR dataset. The average median and average mean of Translation Error (TE in meters) and Rotation Error (RE in degrees) are reported.
Tab. 3: Comparison of different models using different paradigms in both seen and unseen environments on the 360Loc dataset. The average median and average mean of Translation Error (TE in meters) and Rotation Error (RE in degrees) are reported.
Citation
If you find our work useful in your research, please cite:
@inproceedings{zheng2025spr,
title={Scene-agnostic Pose Regression for Visual Localization},
author={Zheng, Junwei and Liu, Ruiping and Chen, Yufan and Chen, Zhenfang and Yang, Kailun and Zhang, Jiaming and Stiefelhagen, Rainer},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025}
}