UniVLN: Universal Vision-Language Navigation
|
1Karlsruhe Institute of Technology
|
2ETH Zurich
|
3MIT-IBM Watson AI Lab
|
|
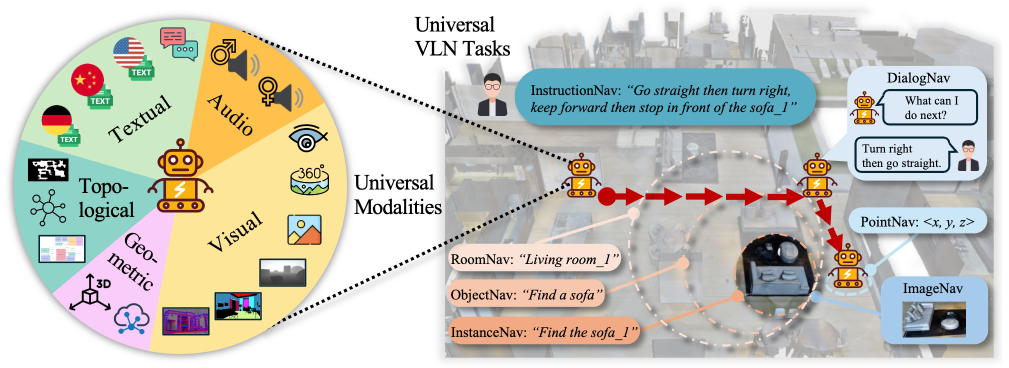
Figure 1: UniVLN benchmark includes 17 modalities, i.e., visual (6), geometric (2), topological (3), audio (2) and textual (4). It unifies 7 VLN tasks under the same trajectory, enabling benchmarking both inter- and intra-task Vision-Language Navigation.
|
Abstract
Existing task-specific Vision-Language Navigation (VLN) datasets face several limitations that hinder the development and evaluation of unified navigators. These include limited task coverage, inconsistencies across benchmarks with varied environments, trajectories, start and goal locations, and restricted input modalities, all of which hinder the generalizability of advanced VLN. To overcome these, we introduce UniVLN, a universal benchmark designed to advance VLN comprehensive training and evaluation significantly. UniVLN uniquely features 17 diverse input modalities, such as texts, dialogs, images with different fields of view (90° to 360°), point clouds, event-based data, audio, semantic masks, and various map representations. The multi-modal data provides agents with a much richer set of perceptual signals than previous datasets. Furthermore, UniVLN acts as a universal platform supporting 7 distinct VLN tasks within a single, consistent environment, ranging from room-goal navigation to complex instruction following and dialog-based guidance, supporting both intra- and inter-task comparison. By combining comprehensive modality diversity with unified task coverage, UniVLN offers a platform for training and evaluating more capable and generalizable VLN models.
Why UniVLN?
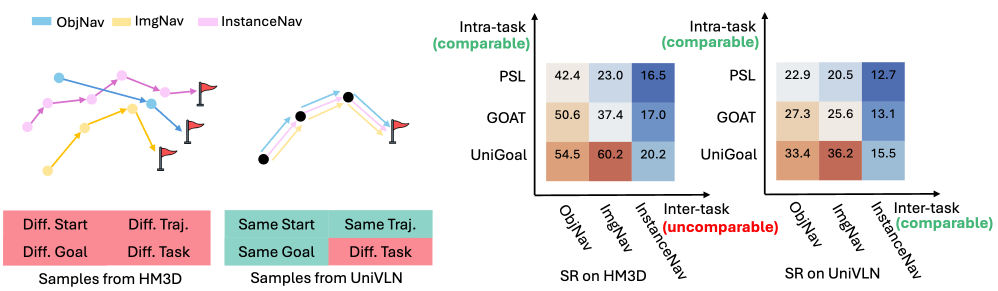
Figure 2: Left: Samples from HM3D and UniVLN datasets among three tasks. Unlike HM3D, our UniVLN unifies task-irrelevant data like start/target/trajectory, enabling reasonable evaluation across tasks. Right: The Success Rates (SR) of unified VLN methods (PSL, GOAT, UniGoal) are comparable on both axes (inter- and intra-task) on UniVLN by keeping task-irrelevant data constant, yielding a comprehensive test for generalized navigators
|

Table 1: Inter-task comparison on UniVLN and HM3D datasets. Success rates (SR) are reported. Results are uncomparable across tasks on HM3D due to the lack of data consistency.
|
Table 1 showcases the inter-task comparison on UniVLN and HM3D datasets. Models perform similarly well in different tasks on UniVLN with consistent simulation environments, starting points, starting orientations, ground-truth trajectories, end locations, and orientations. Evaluating model performance across tasks without controlling task-irrelevant variables (e.g., starting point and orientation) introduces confounding factors, making such comparisons unreasonable. Notably, when evaluated on the inconsistent HM3D dataset, model comparisons can produce contradictory conclusions, as evidenced in Table 1.
Supported Tasks and Modalities
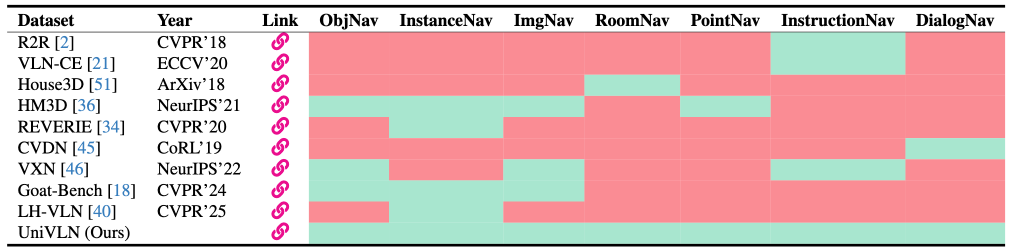
Table 2: VLN task comparison among VLN datasets: green = available, red = not available.
|

Table 3: Input modalities comparison among VLN datasets: green = available, red = not available. Pin: Pinhole; Pan: Panorama; Sem.: Semantic; Occ.: Occupancy; Topo.: Topological; Dial.: Dialog.
|
Experiments
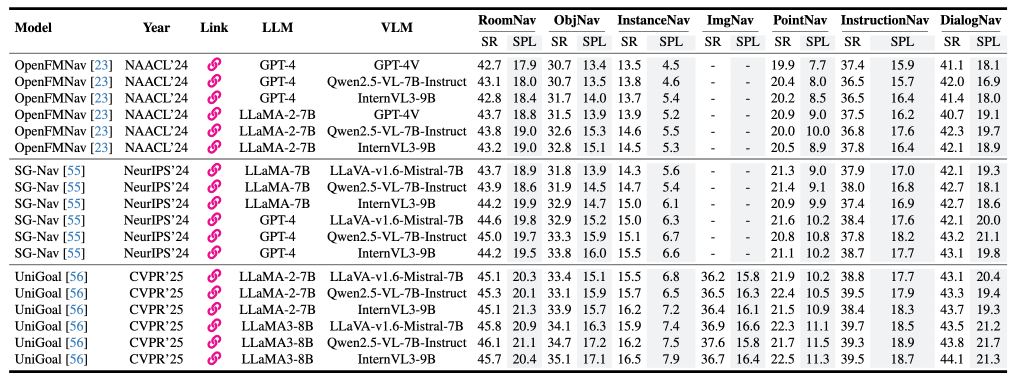
Table 4: Results of different baseline models with different VLMs and LLMs on UniVLN dataset. SR and SPL are in percentages.
|

Table 5: Ablation of different input modalities on UniVLN dataset. Pin: Pinhole; Geo.: Geometric; Topo.: Topological; TM: Topological Map. SR and SPL are in percentages.
|